
Turn e-commerce pages into clean, usable data
Turn e-commerce pages into clean, usable data
ShopScraping scans online stores, collects product data, and organizes it for research, price monitoring, and decision-making. No coding or browser extensions required.
ShopScraping scans online stores, collects product data, and organizes it for research, price monitoring, and decision-making. No coding or browser extensions required.


We extract any publicly available information from product pages. Each product corresponds to a single page (URL).
Options within a page — such as size or color, when they don’t have separate URLs — are defined as variations and handled on demand.
Learn more in our Knowledge base.
We extract any publicly available information from product pages. Each product corresponds to a single page (URL).
Options within a page — such as size or color, when they don’t have separate URLs — are defined as variations and handled on demand.
Learn more in our Knowledge base.
Product Fields We Capture
Product Fields We Capture
Core Info
Title
Brand/Manufacturer
Category
Description
Specification
Pricing & Availability
Regular price
Sale price
Currency
Discount
In stock/Out of stock
Identifiers
SKU
GTIN/EAN
MPN
ISBN
Other IDs
Options
Size
Color
Condition
Package Quantity
Media
Primary image
Gallery images
Reviews & Ratings
Average rating
Review count
Custom Attributes
Any field on request
Automated Data Extraction
Automated Data Extraction
A self-learning system that adapts without manual setup
A self-learning system that adapts without manual setup
A self-learning system that adapts without manual setup
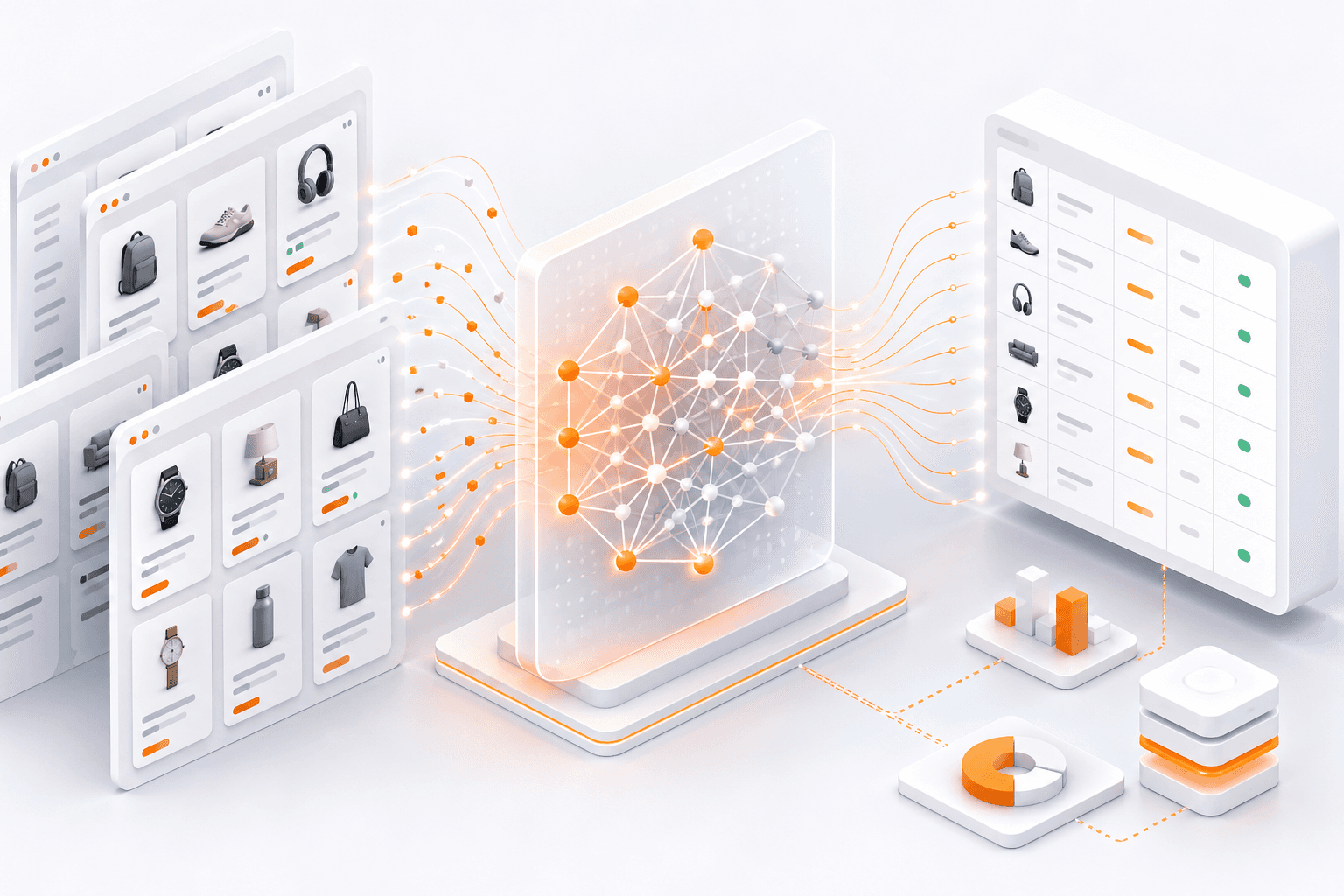
ShopScraping automatically analyzes page structure and extracts key attributes such as title, price, availability, specifications, and additional metadata.
It works across a wide range of e-commerce websites — without predefined templates or custom parsers — making it suitable for product catalog scraping at any scale.
Machine learning–driven models continuously adjust to layout changes, eliminating the need for manual selector updates or ongoing maintenance.
As websites evolve, the system keeps data extraction stable and accurate without human intervention.
ShopScraping automatically analyzes page structure and extracts key attributes such as title, price, availability, specifications, and additional metadata.
It works across a wide range of e-commerce websites — without predefined templates or custom parsers — making it suitable for product catalog scraping at any scale.
Machine learning–driven models continuously adjust to layout changes, eliminating the need for manual selector updates or ongoing maintenance.
As websites evolve, the system keeps data extraction stable and accurate without human intervention.

Scheduled Website Crawling
Scheduled Website Crawling
Fresh insights collected on a continuous basis
Fresh insights collected on a continuous basis
Fresh insights collected on a continuous basis
The platform supports flexible web scraping schedules for continuous price tracking — from one-time runs to monthly, weekly, or daily updates — allowing you to control how often each data source is refreshed based on business needs.
An intelligent scheduling engine distributes requests over time, ensuring stable, uninterrupted data collection even at scale. Built-in retry mechanisms and failure handling guarantee high reliability and minimize gaps, so you can consistently rely on complete and up-to-date results.
The platform supports flexible web scraping schedules for continuous price tracking — from one-time runs to monthly, weekly, or daily updates — allowing you to control how often each data source is refreshed based on business needs.
An intelligent scheduling engine distributes requests over time, ensuring stable, uninterrupted data collection even at scale. Built-in retry mechanisms and failure handling guarantee high reliability and minimize gaps, so you can consistently rely on complete and up-to-date results.
High Accuracy & Quality Control
High Accuracy & Quality Control
Built-in validation, anomaly detection, and flexible attribute extraction
Built-in validation, anomaly detection, and flexible attribute extraction
Built-in validation, anomaly detection, and flexible attribute extraction
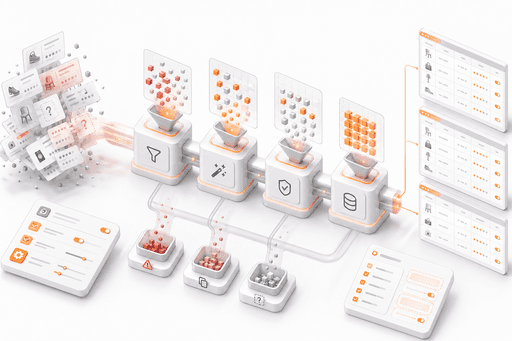
Every stage of the pipeline includes automated validation to ensure high data accuracy and consistency. The system detects anomalies, duplicates, missing values, and invalid records, preventing corrupted or incomplete information from entering your workflows.
Additional normalization and consistency checks ensure that extracted information remains accurate and well-structured, even when page layouts, formatting, or attributes representation change within the same website. This maintains a high level of precision in the final dataset.
The platform also supports custom data extraction, allowing you to define additional fields, attributes, or specific points tailored to your use case. This ensures you get exactly the records you need — not just generic product information.
The result is reliable, structured records ready for competitor price monitoring, pricing strategies, market analytics, and operational decision-making.
Every stage of the pipeline includes automated validation to ensure high data accuracy and consistency. The system detects anomalies, duplicates, missing values, and invalid records, preventing corrupted or incomplete information from entering your workflows.
Additional normalization and consistency checks ensure that extracted information remains accurate and well-structured, even when page layouts, formatting, or attributes representation change within the same website. This maintains a high level of precision in the final dataset.
The platform also supports custom data extraction, allowing you to define additional fields, attributes, or specific points tailored to your use case. This ensures you get exactly the records you need — not just generic product information.
The result is reliable, structured records ready for competitor price monitoring, pricing strategies, market analytics, and operational decision-making.
Multi-Format Data Export
Multi-Format Data Export
Ready for integration with your tools
Ready for integration with your tools
Ready for integration with your tools
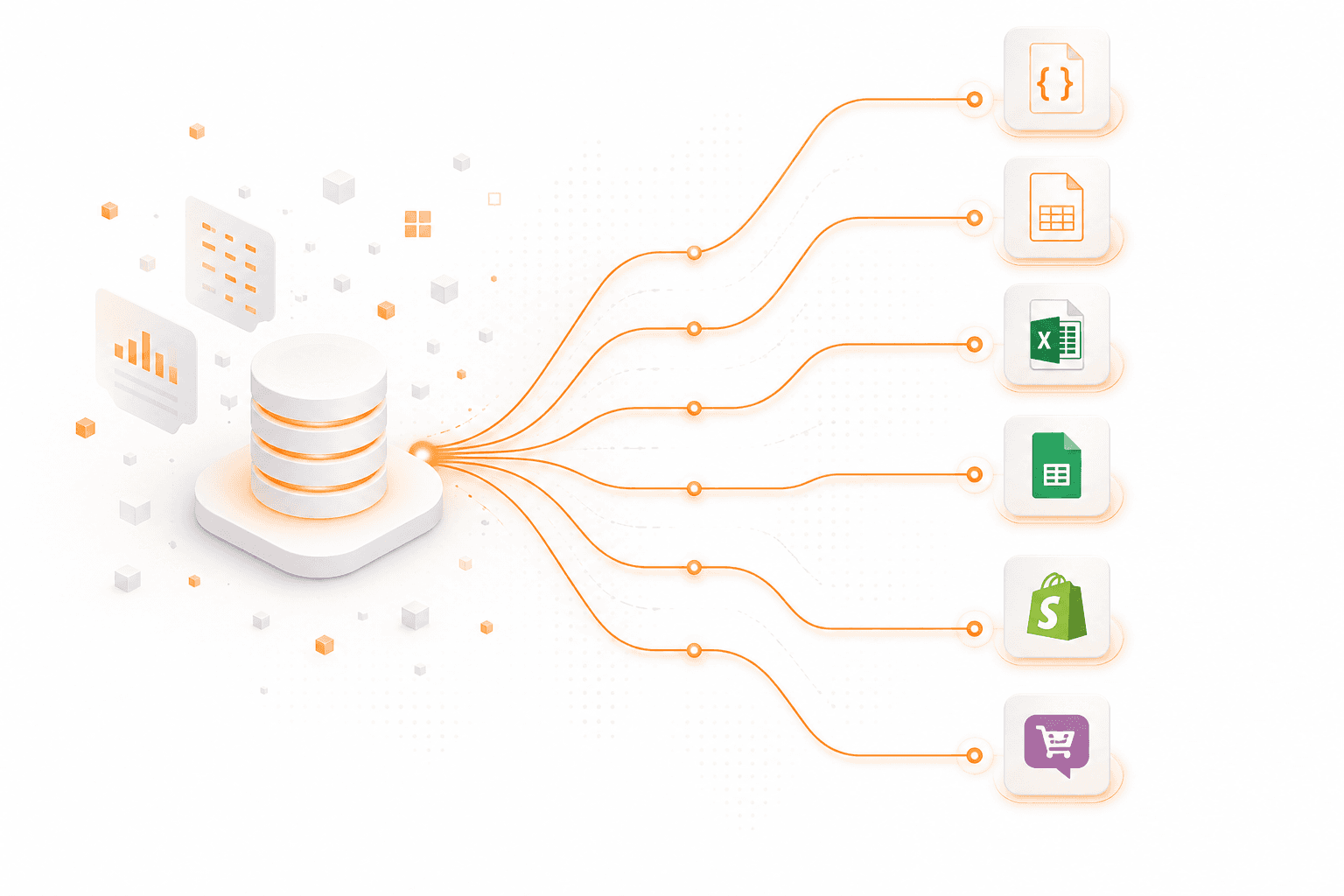
All extracted information follows a unified schema with standardized field names, formats, and data types across all sources.
As a result, insights from different websites can be directly compared, analyzed, and integrated into your systems without manual cleanup or transformation.
All extracted information follows a unified schema with standardized field names, formats, and data types across all sources.
As a result, insights from different websites can be directly compared, analyzed, and integrated into your systems without manual cleanup or transformation.
Export data in formats ready for your workflow:
Export data in formats ready for your workflow:
Export data in formats ready for your workflow:
CSV
JSON
Excel (xlsx)
Google Sheets
CSV
JSON
Excel (xlsx)
Google Sheets
Shopify
WooCommerce
Other formats upon request
Shopify
WooCommerce
Other formats upon request
Get Started in Minutes
Set up your first data extraction in just a few clicks
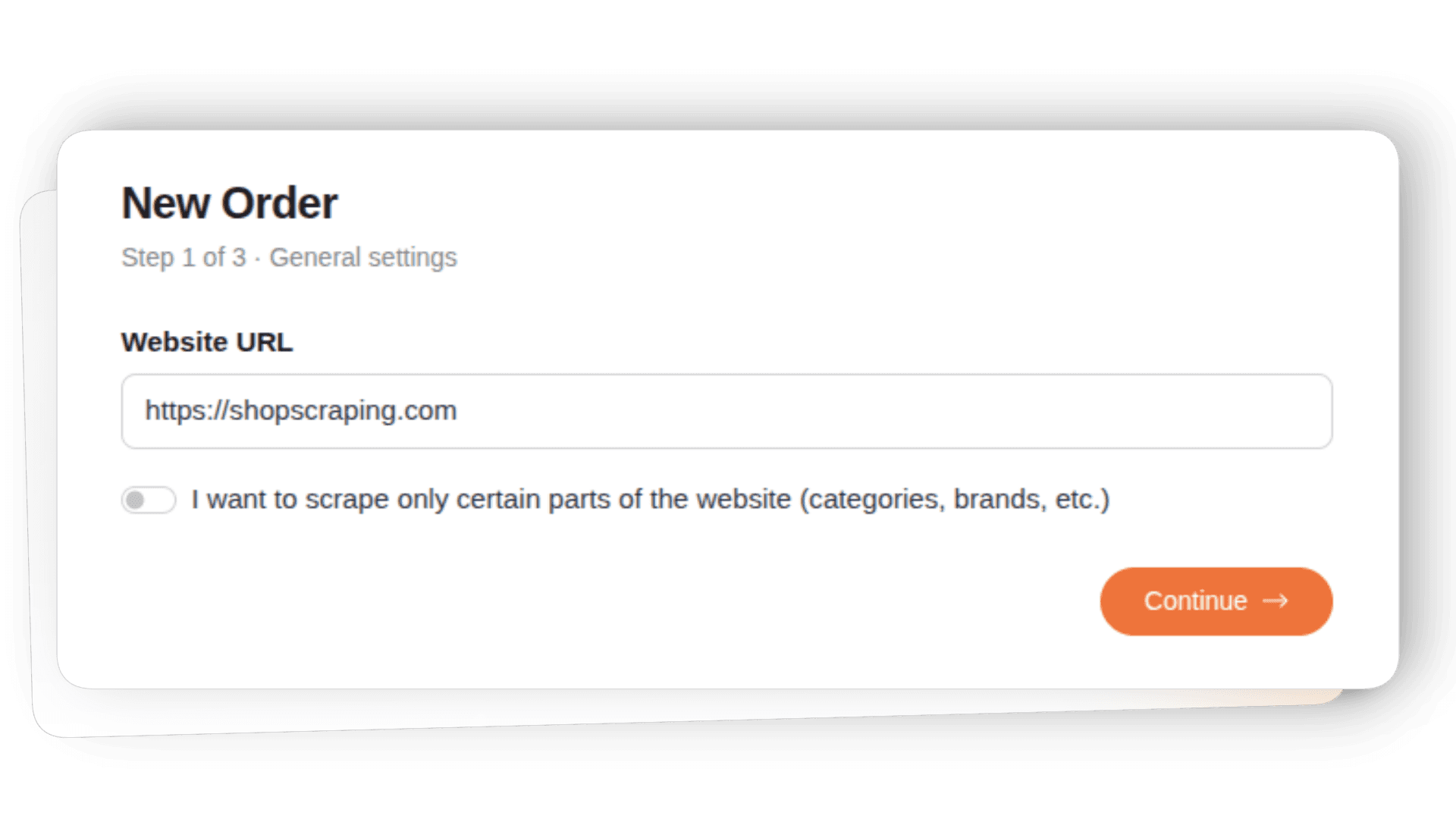
1
Enter a website URL
Add the product or website URLs you want to track. You can include product pages, categories, or competitor sites.
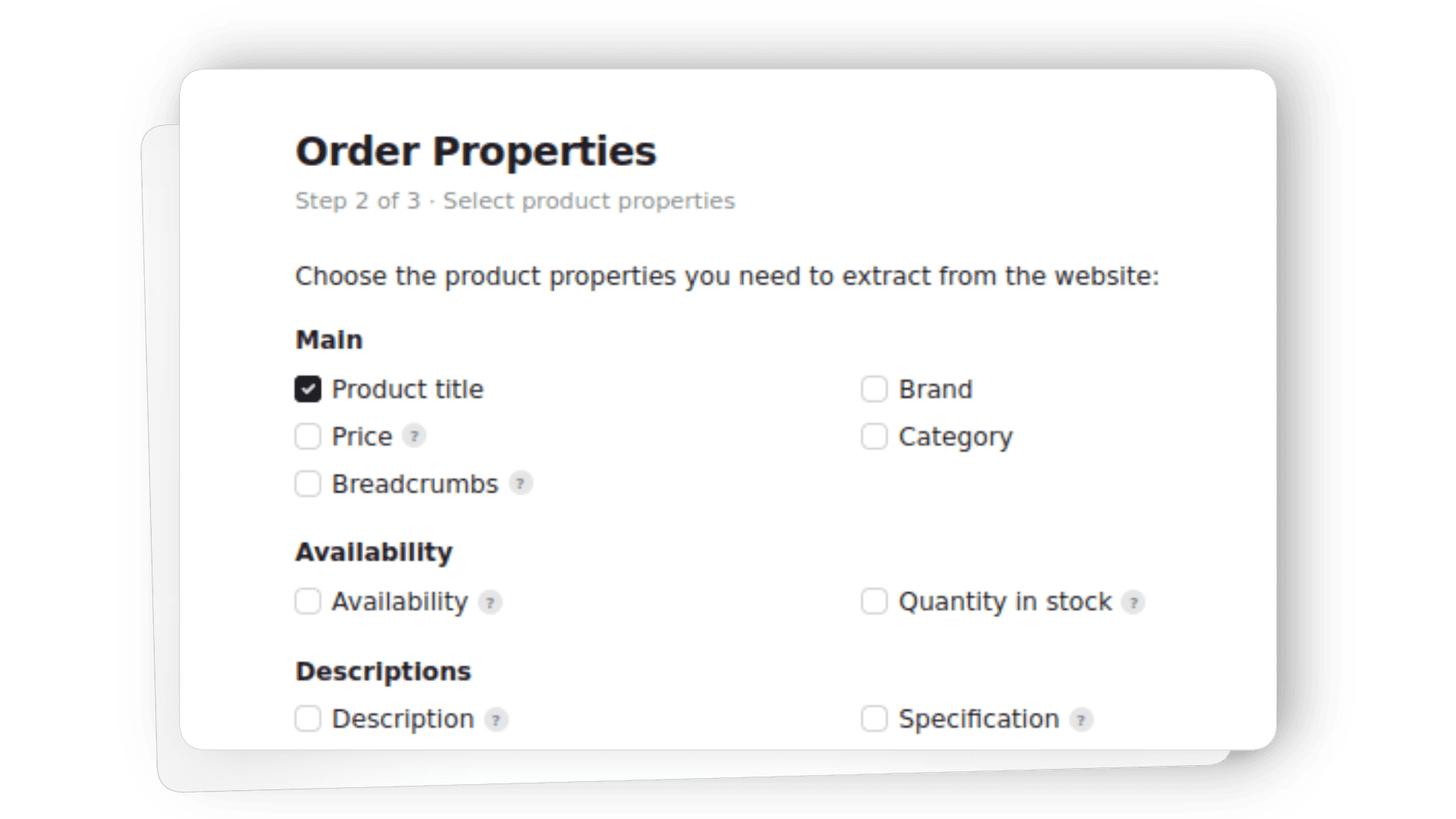
2
Choose what data to extract
Select the fields you need, such as pricing, availability, or product details. Customize the dataset to match your use case.
3
Run & get results
Receive clean data in CSV, Excel, or JSON as soon as processing is complete. Run one-time collections or schedule recurring extractions.
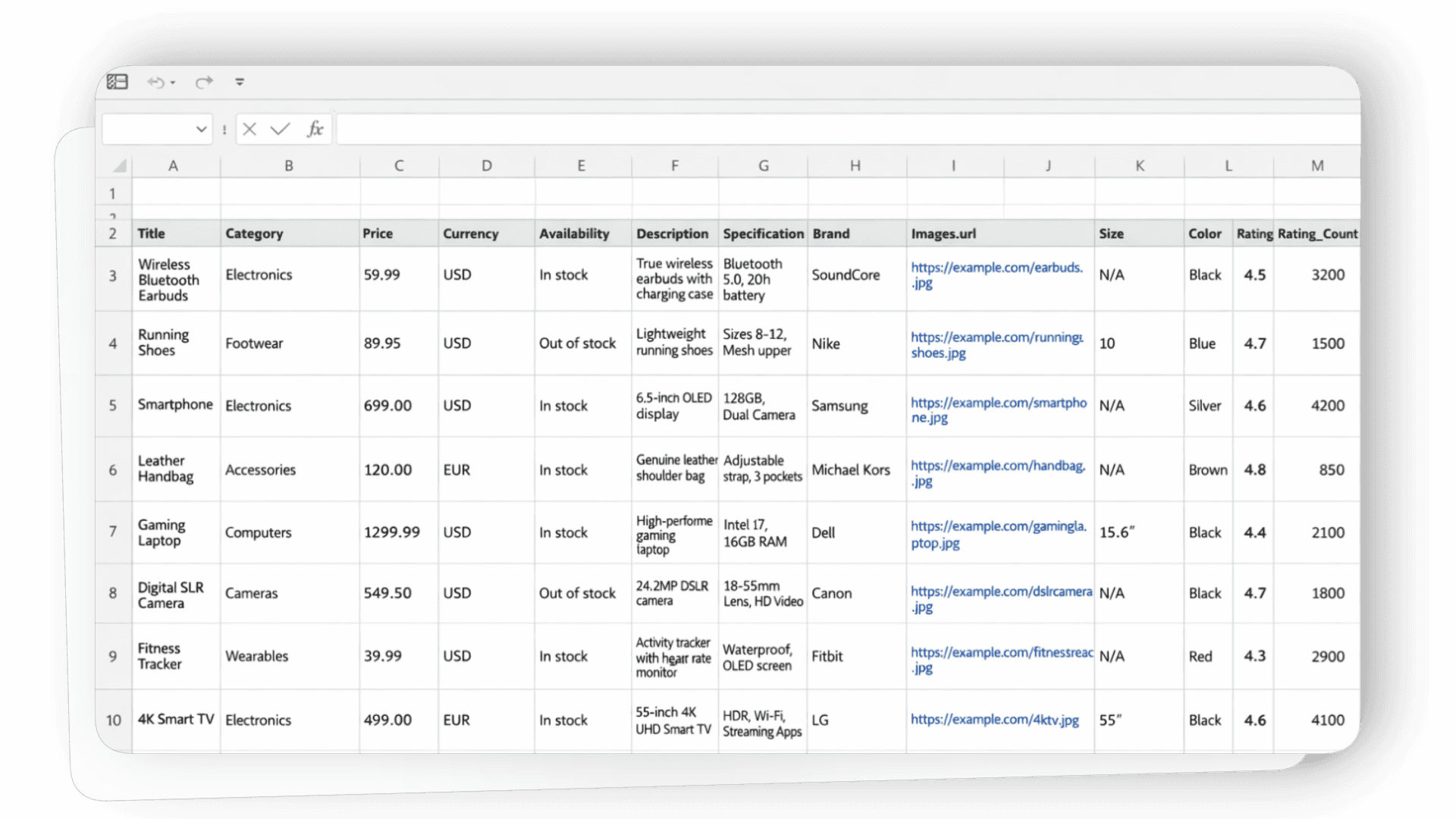
Clean, structured datasets for immediate use
No setup, no code. Just paste a URL and get your first dataset.
Clean, structured datasets for immediate use
No setup, no code. Just paste a URL and get your first dataset.
© 2026 ShopScraping
© 2026 ShopScraping
© 2026 ShopScraping
© 2026 ShopScraping